
🚨 문제 발생
런칭 페스티벌이 끝나가는 오후 3시 50분 즈음, 여러 크루로부터 정상적이지 않은 웹사이트 응답이 내려온다는 이야기를 들었다. 직접 개발자 도구에서 확인해보니 꾸준하게 500 응답 코드를 내려주고 있었다. 뒤쪽에서 무언가 문제가 발생했다.
서버가 켜진 지는 3시간이 다 되어 가던 때였다. 런칭 페스티벌 직전에 몇 가지를 수정해 릴리즈했기 때문에 업타임이 길지는 않았다. API의 정상 동작을 확인했고, 처음 두 시간 정도는 모니터링 상에서도 큰 이슈가 존재하지 않았었다.
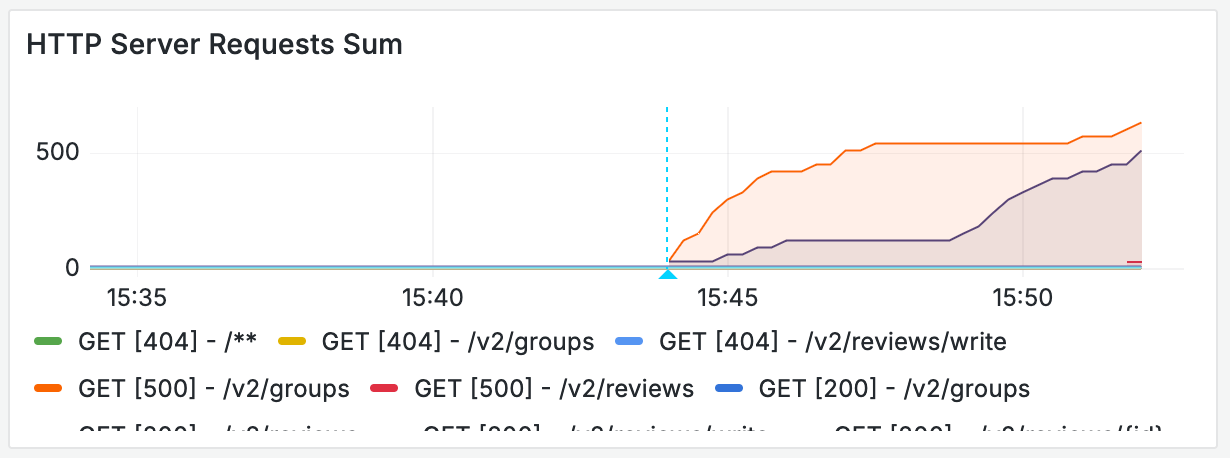
어플리케이션 로그는 즉각 확인할 수 있었으므로 DB 서버에 문제가 생겼다는 의심이 먼저 들었다. DB 쪽의 로그/매트릭을 달지 못했던 상황이라, 직접 SSH를 통해 접근을 시도했으나 터미널은 묵묵부답이었다. 시간을 빠르게 흘러가고, 사용자는 끊임없이 요청하고 있었다. 야속하게도 우리 API에서는 500 예외를 전달해줄 수밖에 없었다.
결국 AWS에서 직접 인스턴스를 재구동했다. 다시 DB 서버와 어플리케이션을 켰고, 정상적으로 작동하는 데에 안도했다… 만, 원인을 몰랐기 때문에 찝찝했다. 방학 동안 내내 로그와 매트릭을 들여다보아야 했고, 캠퍼스에 갈 수 없어 가설을 검증할 방법도 없었기에 참 답답했다. 레벨 4가 시작된 뒤로도 이틀간 원인을 찾아나섰는데, 이제야 그 원인을 알아내 글로 공유하고자 한다.
🖥️ 어플리케이션 로그, 모니터링 확인하기
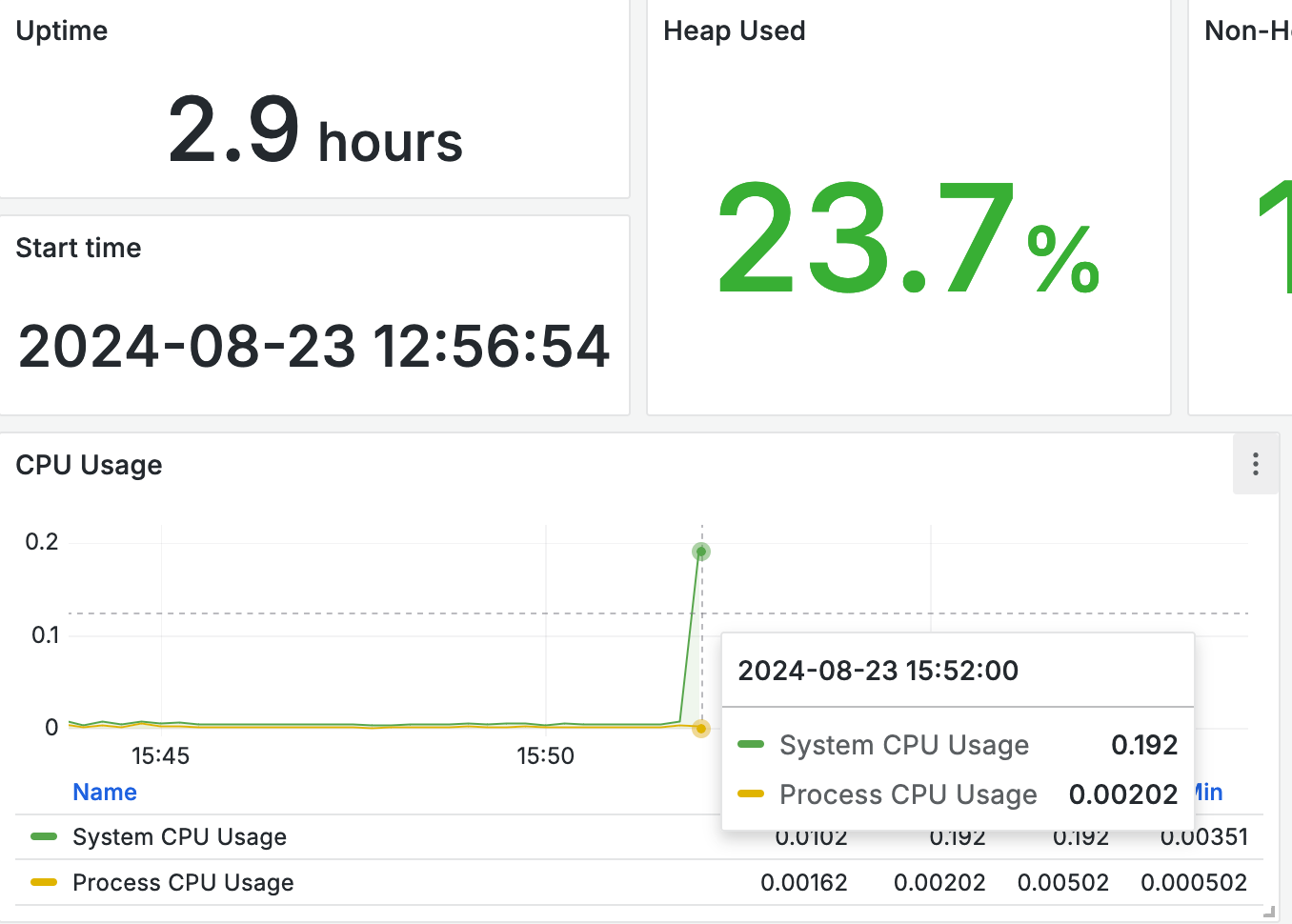
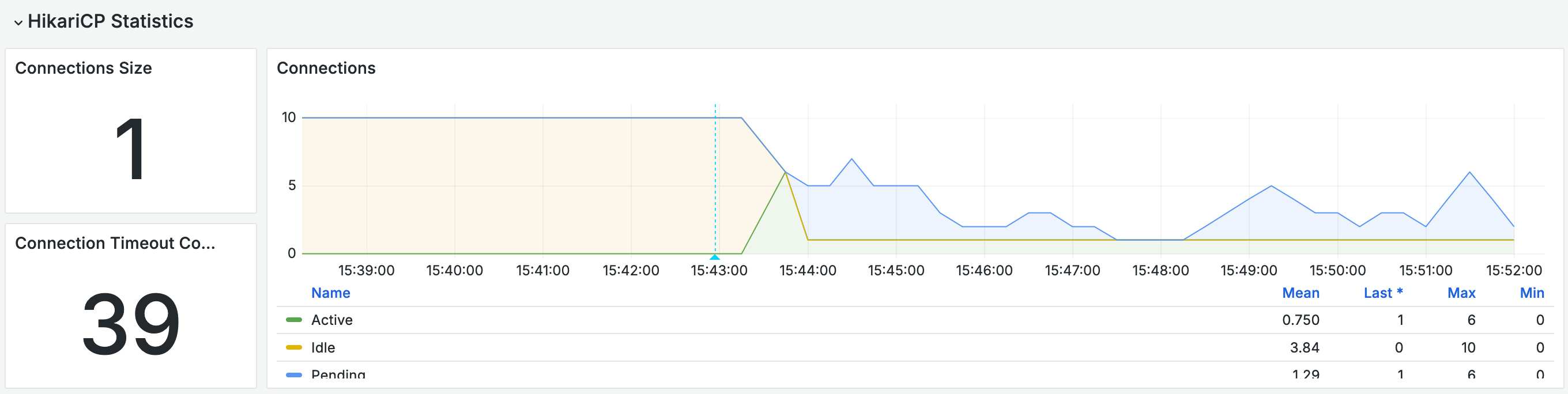
가장 눈에 띈건 HikariPool의 커넥션 상황이었다. 어느 순간부터 커넥션 풀의 개수가 10개에서 대폭 줄어들더니, 사용 중인 커넥션이 1개로 고정돼 더 이상의 커넥션을 가져오지 못하는 상황이었다. 풀에서 커넥션을 요구한 지 30초가 지나 예외가 발생하기도 했다.

어플리케이션 로그에서는 DB 서버와 연결할 수 없다는 이야기도 함께 내뱉었다. 어플리케이션에서 DB로 패킷은 정상적으로 전달되었지만, DB 드라이버가 패킷을 받지 않았다는 로그를 확인할 수 있었다. 이 로그는 처음 발생한 44분부터 52분까지 지속되었으며, 이후에 어플리케이션과 DB 서버를 재구동했다. (그때 당시에는 아무것도 모르고 두 쪽을 다 내렸다 올렸는데, 지금 생각하면 참 무지했다.)
추가로 우리가 확인할 수 있는 건 DB 서버의 정보다. 우리가 미처 DB서버에 매트릭 정보와 로그 설정을 해두지 않았어서 꽤나 머리가 지끈할 것 같았던 곳이다. 매트릭 정보가 없으니 아마존에서 제공하는 경량 메트릭을 확인해볼 수밖에 없었다.

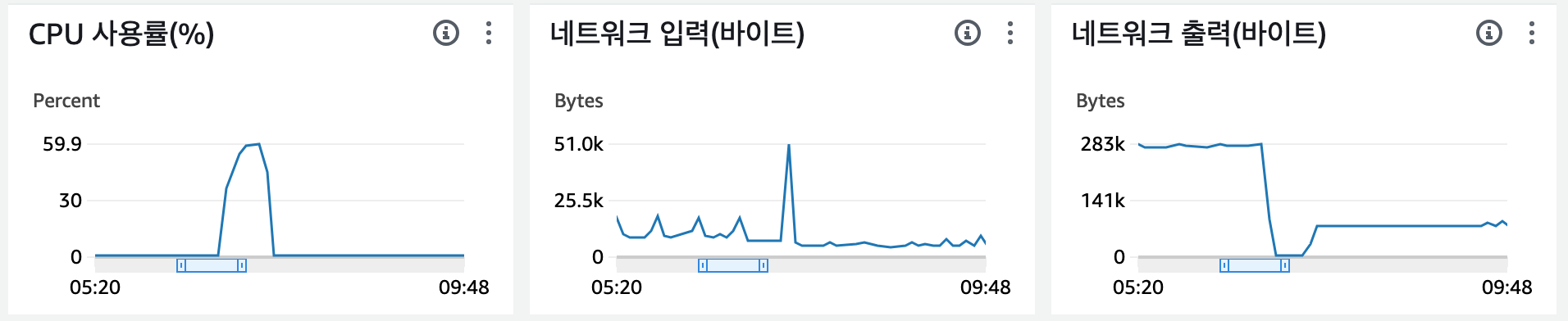
매트릭이 위로 솟구쳤다가 떨어진다. 35분까지는 바닥에 붙어 있던 CPU 사용량이 40분부터 스멀스멀 올라온 것으로 보아하니, 이쯤부터 DB 서버에 문제가 발생한 것으로 파악된다. DB 쪽에서 로그를 확인할 수 있으면 좋을텐데, 라고 아쉬워하고 있었다. DB에서는 직접 설정을 켜 두어야 로깅이 활성화되는 듯했다.
🪵 DB 모니터링, 로그 확인하기
혹시나… 하는 마음에 DB 서버에 마운트해둔 폴더로 접근해 보았는데, 선물 몇 개가 들어있었다 🥹 binary log가 저장돼 있어서, 여기에서 실마리를 얻을 수 있지 않을까? 라는 생각을 하게 되었다. 문제가 된 부분은 8월 23일 15시 35~40분 사이이다.
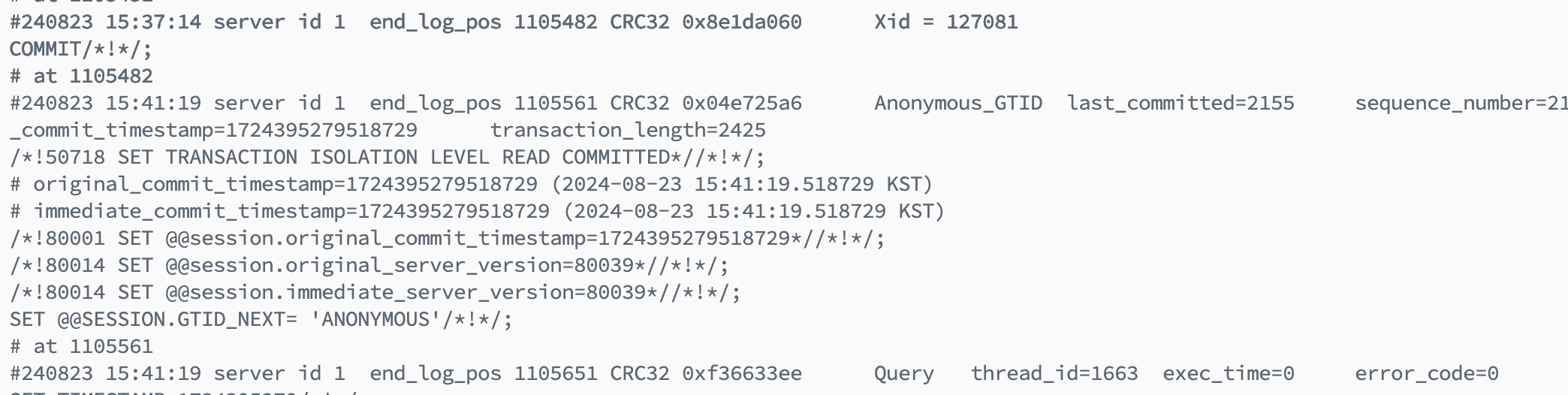
의심했던 것과는 정반대로, DB 서버는 묵묵히 할 일을 해나가고 있었다. DB의 마지막 커밋 시점은 15:42:56이었다. 위 히카리풀 그래프의 파란 점선이 해당 시점이다. DB는 해당 시점 이후로 제대로 커밋하지도, 읽어오지도 못하고 있었다. 물론 바이너리 로그도 남아있지 않았다.
우리가 해당 사실을 확인하고, DB 서버 EC2를 재시동한 시점은 15:57 근처다. 15:42를 마지막으로 추가 커밋 등의 로그가 존재하지 않았던 것을 보아 DB 서버가 문제라는 생각은 여전히 하고 있지만, 어떤 부분에서 문제가 되는지를 확인할 수 없었다.
📦 DB 인스턴스의 OS syslog 확인하기
포케가 ‘리눅스 시스템 로그’를 확인해보라는 귀띔을 줬다. /var/log 에 저장되는 다양한 로그가 저장되는데, 이 중 syslog에서 이번 문제의 원인과 해결책을 찾아볼 수 있었다.
결론부터 말하자면, 스왑 메모리가 존재하지 않았던 EC2 인스턴스의 커널에서 메모리 부족으로 인해 MySQL 서버를 종료시켰다. 운영 서버의 EC2 환경을 고려하지 않았다는 것도 참 웃기다.. 1G 남짓한 메모리에서 돌아가는 MySQL 서버는 언제 죽어도 이상하지 않았다…
로그에는 아래와 같은 내용이 담겨 있었다.

invoked oom-killer, Killed process (mysqld). 메모리 부족으로 인해 커널이 mysql을 처리했다는 내용이었다. 1G 메모리의 절반 이상을 차지했던 MySQL을 커널이 정리하면서 로그를 남겨뒀다.
🔍 이제야 보이는 수치
DB 서버가 종료되었다는 사실을 알고 나니, 모든 시계열 정보와 로그 등의 퍼즐이 맞춰지기 시작했다. 커넥션 개수가 점점 줄어들었다는 사실은 HikariCP를 조금 공부하면 알 수 있었다. HikariCP에서는 커넥션을 어플리케이션에게 제공하기 전에 커넥션을 검증한다. 아래는 해당 코드 중 일부다.
// HikariPool.java:168
// isConnectionDead()에서 Connection이 유효한지 확인
// 유효하지 않다면, 현재 커넥션 풀에서 제거
// ...
if (poolEntry.isMarkedEvicted() ||
(elapsedMillis(poolEntry.lastAccessed, now) > aliveBypassWindowMs &&
isConnectionDead(poolEntry.connection))) {
closeConnection(poolEntry, poolEntry.isMarkedEvicted() ? EVICTED_CONNECTION_MESSAGE : DEAD_CONNECTION_MESSAGE);
// ...
// HikariPool..java:430
// 커넥션 풀에서 제거한 뒤, 필요한 만큼 커넥션 생성
// ...
void closeConnection(final PoolEntry poolEntry, final String closureReason)
{
if (connectionBag.remove(poolEntry)) {
// ...
if (poolState == POOL_NORMAL) {
fillPool(false);
// ...
어플리케이션에서 커넥션을 요구할 때, DB 서버가 종료되었으므로 유효하지 않은 커넥션이다. 따라서 커넥션 풀에서 제거된다. 문제는 새로운 커넥션을 들고올 수도 없다. 앞서 봤던 커넥션 개수 그래프가 이해되는 순간이었다.

남아있는 한 개의 커넥션도 결국에는 실제로 연결되어있는 커넥션이 아니기 때문에, DB 커밋을 요청하고 이를 기다리고 있는 것으로 보였다. 커넥션의 개수가 작아지고 모든 커넥션이 사용 중(사실은 없지만)이므로, 어플리케이션의 요청은 30초동안 기다리다 예외를 맞고 돌아서게 된다. 사용자는 500 예외를 맞이한다.
🤨 누가 방아쇠를 당겼을까?
분명 메모리가 부족했던 것은 사실이었지만, 잘 돌아가던 DB 서버에서 MySQL 서버에 부하가 일어날 만한 이유를 찾아야 했다. 어플리케이션에서는 HikariCP를 통해 커넥션 관리를 하고 있어 추가적인 커넥션이 발생하지 않을 것이라고 추측했다. 외부 요인이 존재해 메모리를 더 잡아먹는 친구가 존재할 것이라고 생각했다.
syslog를 기반으로 여러 로그들을 돌아다니던 중에 흥미로운 활동을 발견했다. 마지막 커밋 기록이 15:42 근처니, 이 근처에서 어떤 일이 일어난지를 알아보아야 했다. 실제로 네트워크 입/출력이 올라간 시점과도 일치했다.
2024-08-23T15:42:58.487449 systemd[1]: Starting apt-daily-upgrade.service - Daily apt upgrade and clean activities…
일일 apt 업그레이드를 한단다. apt update의 귀찮음을 줄이기 위해 스케줄링되어있는 Job이었는데, 이에 해당하는 로그도 확인할 수 있었다.
Log started: 2024-08-22 16:06:56 (Reading database ... (Reading database ... 5% (Reading database ... 10% ... (Reading database ... 95% (Reading database ... 100% (Reading database ... 101697 files and directories currently installed.) Removing linux-aws-tools-6.8.0-1013 (6.8.0-1013.14) ... Log ended: 2024-08-22 16:09:05
원래라면 이렇게 2-3초면 해결되는 게 (추가 업데이트할 것이 없다는 이야기다), 하필이면 그 시간대에 apt update를 할 게 생겨버려서 발생한 문제다. 실제 로그에는 14분 가량의 apt update가 이루어졌다. 아마 이 사이에 OOM으로 인해 몇 가지가 더 꼬여버린 것 같지만, 이 친구가 메모리 부족의 트리거를 당겨버린 듯했다. 이 친구가 메모리를 200메가나 잡아먹는단다… MySQL이 500M 넘게 잡고 있었으니, OS가 나머지를 챙긴다면 추가로 들어갈 방은 확실히 존재하지 않았겠지.apt-daily-upgrade.service: Consumed 24.378s CPU time, 215.1M memory peak, 0B memory swap peak.
🤯 한 번으로는 안 끝나
바로 다음 날, 새벽 6시부터 스프링 서버가 죽어버리는 일이 또 발생했다. 지금이야 당연히 스왑 메모리가 없다는 것을 알고 있으니 원인을 바로 알 수 있었지만, 그 당시에는 진짜 왜 죽었는지에 대한 단서가 또 없었다. 방학이 시작된 뒤라 직접 찾아가볼 수도 없어 또다시 이런저런 가설만 세울 뿐이었다.
스왑 메모리는 프로덕션 서버에도 설정되어있지 않았고, 같은 방식으로 높은 네트워크 트래픽이 동반됐다.
마찬가지로 syslog부터 열어봤고, oom-killer가 이번에는 java 프로세스를 직접 꺼버렸다(…)kernel: Out of memory: Killed process 69224 (java) total-vm:2967296kB
이 배후는 nginx였다. 현재 운영 서버에서는 nginx와 스프링이 함께 돌아가고 있었는데, 이 기회에 nginx를 밖으로 뽑는 것을 고려해보게 되었다. 물론 스왑 메모리가 우선되어야겠지만.. 다행히 Github를 활용한 CD가 가능했기에, 원격으로 서버를 다시 올리게 되었다. oom-killer가 깃헙 러너와 자바를 함께 보내버렸다면.. 생각만 해도 끔찍하다 😮💨
산초가 잠실에 약속이 있어서, 너무나도 고맙게도 관련 로그 + 스왑 설정을 방학 때 진행할 수 있었다. 메모리 부족으로 인한 종료였기에 로그를 통해 원인을 알 수 없어 참 답답했던 방학이었다. 두 번이나 서버가 뒤집어졌고, 원인을 몰랐기에 추가적인 사고가 방학 중에 일어나도 이상할 게 없었다. 신경을 곤두세우고 매일같이 모니터링을 보면서 잘 살아있나.. 안부를 확인했다. 한 번 배포된 서비스는 안정적으로 사용자가 활용할 수 있어야 했으니까.
🐾 자취를 남기자
리눅스가 참 감사했다. 이런저런 로그를 남겨두고 있었던 덕에 (커널 레벨이었지만) 문제 상황을 파악할 수 있었다. 메모리가 작은 인스턴스의 경우에는 스왑 메모리를 항상 켜두라는 조언이 있었는데, 실제로 메모리가 모자란 상황에서 커널이 어떻게 대처하는지도 알 수 있었다. 여러모로 많이 배우게 되었다.
어플리케이션단의 로깅도 중요하지만, 모니터링을 통한 시계열 및 로그도 중요하다는 사실도 알게 되었다. DB 서버에는 깜빡하고 매트릭 정보를 수집하지 않고 있었는데… 🥲 월요일에 캠퍼스 출근하고 나서 제일 먼저 한 일이 모자란 모니터링 정보 메꾸기였고, 하나둘씩 정보의 구멍이 메워지고 있다.
무엇보다도, 어떻게든 물고 늘어지면 실마리가 하나둘씩 나온다는 점이 참 신기하면서도 즐거웠다. 험난한 발걸음에 힘을 준 산초와 포케에게 다시한번 감사를… 🥹 (작은 메모리에는 꼭 스왑 메모리를 설정하자)