
🪨 그만 괴롭혀요 DTO
몇 달간 백엔드 팀을 괴롭힌 주제가 있다. DTO 매핑과 그 깊이인데, 그 시작은 엔티티 연관관계까지 거슬러 올라간다. 🚀 JPA를 활용한 엔티티 연관관계의 기준을 무엇으로 할 것인가? 에 대한 결론이 어느 정도 수립돼 있었기에, 새로운 도메인이 등장하거나 요구사항이 등장하더라도 어렵지 않게 추가하거나 변경할 수 있었다. 네 명이 다같이 데이고 공감한 부분이 많다보니, 함께 싱크를 맞춰나가는 것도 어렵지 않았다 🙂
리뷰미의 코드는 크게 ReviewGroup, Review, Template, Highlight 네 가지의 패키지로 나누어져 있다. 패키지가 나누어져있는 만큼 외부 패키지에 존재하는 엔티티를 직접 참조하지 않으려 하고 있다. 덕분에 도메인의 경계가 명확하게 나누어졌다. 추후에 분산 환경에서도 API 연산의 결과를 활용해 조합하는 것이 편리할 것이라고 내다보았다. (이 생각이 현재 문제의 발단이 된 것일지도..)
리뷰미 서비스의 CRUD 연산 중 CUD 연산은 가볍게 서비스 레이어에서 구현할 수 있었지만, 유독 조회 연산에서 많은 시간을 들이고 있었다. DTO가 깊기도 하고, 여러 레이어를 넘나들면서 많은 정보를 한 곳에 담아야했기 때문이다. 연관관계가 없었으니 ID를 활용해 직접 Repository를 찔러봐야 했다. 이런 부담을 덜기 위해 응답 DTO를 매핑하는 Mapper 클래스를 만들었다. 서비스 클래스의 private 메서드를 하나의 클래스로 뽑아낸 셈이다. 테스트도 가능해졌고 처음에는 괜찮아 보였다…만
조회 로직에서 이렇게 많은 공수가 들어가도 되는가? 에 대한 회의감이 들었다. CUD에서 진행하던 메서드의 길이와는 차원이 달랐다. 리뷰미의 리뷰 하나는 아래와 같은 DTO 구조를 가지고 있다.
TemplateResponse
ㄴ Template Properties
ㄴ SectionResponse
ㄴ Section Properties
ㄴ QuestionResponse
ㄴ Question Properties
ㄴ OptionGroupResponse
ㄴ OptionGroup Properties
ㄴ OptionItemResponse
ㄴ OptionItem Properties
…😵😮💨 나름 위계를 가지고 있는 객체들끼리의 응답을 보내주려다보니 많은 객체들의 사정을 알아야 하는 큰 DTO가 되었다. 깊이도 4-5가 넘어갔다. 하나의 DTO를 매핑하기 위해서 내부 DTO를 만들어야 하고 또 그 안을 만들어야 하고.. 쉽지 않았다. 우테코 안의 다른 팀 크루들에게 DTO 얼마나 깊은지 물어봤지만 이렇게 깊지는 않았다고.. 깊어도 다들 이런 매핑을 하고 있다고… 개발하면서 불편함을 느꼈는데 잘 풀리지 않아 답답한 마음이었다. 제법 지쳐가기도 했다. 큰 패키지도 아니고, 겨우 조회 하나에서 많은 힘을 들여야하는 게 생각보다 쉽게 받아들여지지 않았다. 오히려 이건 귀찮은 거고 당연히 해야하는 것이였을까?
게다가 각각의 매핑을 진행하기 위해서는 DB와의 소통이 필수였는데, 하나의 매핑 과정에서 하위 DTO 개수의 곱연산으로 쿼리가 많이 날아가게 되었다. 이 상황을 또 방지하기 위해 한 번에 매핑에 필요한 모든 객체를 Map으로 미리 불러오기도 했다.
@Transactional(readOnly = true)
public ReviewsGatheredBySectionResponse getReceivedReviewsBySectionId(ReviewGroup reviewGroup, long sectionId) {
// ..
Map<Question, List<Answer>> questionAnswers = getQuestionAnswers(section, reviewGroup);
List<Long> answerIds = questionAnswers.values()
.stream()
.flatMap(List::stream)
.map(Answer::getId)
.distinct()
.toList();
List<Highlight> highlights = highlightRepository.findAllByAnswerIdsOrderedAsc(answerIds);
return reviewGatherMapper.mapToReviewsGatheredBySection(questionAnswers, highlights);
}
🧙🏻♀️ 어떻게 해결할 수 있을까?
팀 내부에서는 그렇다할 방책이 떠오르지 않았다. ‘매퍼 타도 스레드’를 만들어 여러 이야기를 나눠 보기도, 구글에 ‘깊은 DTO’를 검색하면서 다른 방법을 생각해보기도 했다. CQRS라는 패턴이 지금 도움이 될 지도 생각해보았고, 조회용 엔티티들을 만들어 한 번에 여러 객체를 가져오는 것도 생각했었다. 당연한 건지 괜찮은 성과를 내지는 못 했다. 결국 네오에게 손을 뻗어 도움을 요청했다.
네오의 첫 마디는 ‘한 방 쿼리 왜 안 짰어요?’ 였다..?

사실 한 방 쿼리를 고려하지 않은 건 아니었다. 다만 DTO가 깊어지면서 작성해야 하는 쿼리 또한 길어지고 지저분해진다고 느꼈다. 여러 JOIN이 성능을 저하시킬 것이라고 예측했고 쉽게 행동으로 옮기기 어려웠다.
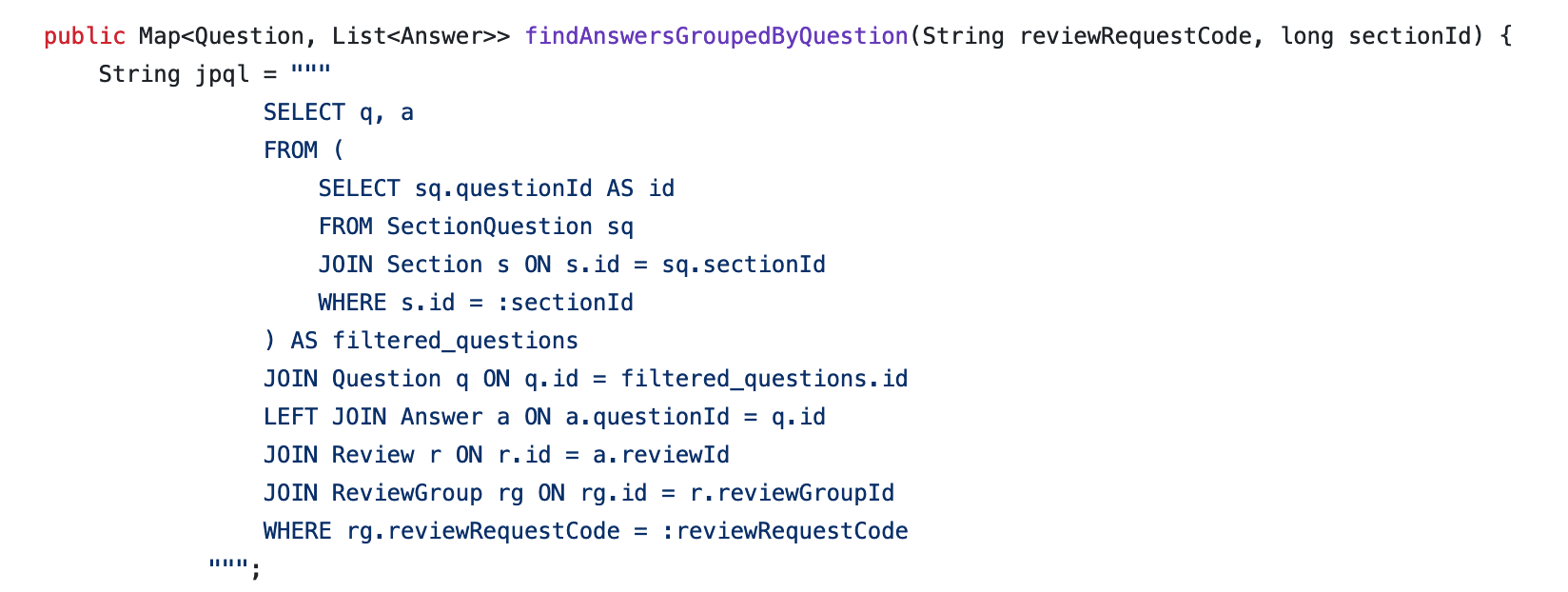
🥕 의사결정의 과정이 중요하다
네오는 이런 코드를 보고 괜찮아 보인다고 하셨다. 의사소통을 통해 합의된 사항이라면 뭐든 어떻느냐는 이야기다.그러면서도 몇 가지를 진단해주셨는데, 우선 우테코에서의 교육과 현업에서의 일은 확실히 다르다는 거다. 클린 코드, 10줄 이상 메서드 작성하지 않기, 과한 의존 삼가기 등 다양한 내용을 체화하면서 저절로 몸이 가지 않는 상황 아래에 놓였었다. 솔직하자면 3-4줄이 넘어가는 쿼리는 ‘무언가 잘못되었다’라는 생각과 함께 손이 먼저 나설 수 없었다.
아주 큰 트레이드 오프가 이런 상황에서 발생한다. 한 방 쿼리로 매퍼를 대체할 수 있을 것 같은데 왜 안 짰을까? 현업에서는 100, 1000줄의 한 방 쿼리를 짠다고도 한다. 조인이 많이 발생하더라도, 인덱스를 잘 태운다면 효율적이다. JOIN이 실제로 모든 테이블을 스캔하는 건 아니기 때문이다.
😮💨 그럼에도 욕심이 과했다
엔티티에서 연관관계를 끊었고, 이를 매핑 형식으로 가져갔다면 분산 환경을 고려했다고도 볼 수 있다. 실제로 패키지 간 참조를 최대한 지양하려고 했고, 이게 무의식 한구석에 자리잡으면서 능률을 떨어뜨렸다고도 생각한다. 네오는 분산 환경을 고려했다면, 한 번에 매핑하는 것이 서버의 책임인지 생각해보아야 한다고 하더라. 클라이언트 쪽에서 우리한테 여러 번 요청을 날려서 합치는 게 낫지 않을까? 혹은, 프록시 서버를 하나 더 두어서 그 서버가 각각의 분산 서버에 요청하고, 이를 수합해야 하지 않을까? 라는 질문거리를 남겨 주셨다.
분산 환경을 고려했다면 매핑 책임이 서버에게 있는지 고민해야 했고, 그렇지 않았다면 한 방 쿼리를 작성하거나 끊어둔 연관관계를 다시 맺는 방법을 고려할 수 있다. 둘 다 챙기려다가 이도저도 못한 상황이 되었다고 진단해 주셨다. 팀원들이 이 내용을 듣고는 다들 고개를 끄덕였다.

🎁 정리해보면
- 네오가 보기에는 지금도 괜찮다 (사실 처음에 보고 ‘이거 왜 한 방 쿼리로 안 짰어요? 라고 했다)
- 엔티티에서 연관관계를 끊었고, 이를 매핑 형식으로 가져갔다면 분산 환경을 고려한 것 같다. 한 방 쿼리로 매퍼를 대체할 수 있을 것 같은데 왜 안 짰는가? 현업에서는 100, 1000줄의 한 방 쿼리를 짜기도 한다. 조인이 많이 발생하더라도, 인덱스를 잘 태운다면 효율적이다.
- 분산 환경을 고려했다면, 한 번에 매핑하는 것이 서버의 책임인지 생각해보아야 한다. 클라이언트 쪽에서 우리한테 여러 번 요청을 날려서 합치는 게 낫지 않을까? 혹은, 프록시 서버를 하나 더 두어서 그 서버가 각각의 분산 서버에 요청하고, 이를 수합해야 하지 않을까?
- 분산 환경을 고려하지 않았다면, 앞에서 이야기한 대로 한 방 쿼리를 작성할 수도 있고, 혹은 끊어두었던 연관관계를 다시 맺어주는 방법도 존재한다.
- 현재 리뷰미는 API 한 개에 대응하는 DTO를 하나 가지고 있다. DTO의 재사용성이 0인 셈인데, 이럴 거면 DTO 안에 내부 Inner class를 만드는 게 낫지 않았을까?
- REST API의 한계를 느끼고 있지는 않을까? 분산 환경에서의 여러 요청이 불편하다면 GraphQL을 사용해볼 수 있다 (Underfetching problem)
백엔드, 프론트엔드 모두 고려해보아야 하는 사안이라 회의를 열어봐야 한다. 어떤 방식으로 유연하게, 그리고 만족스럽게 해결할 수 있을까 🤔